
0x00 (简介)
dgraph是问世没几年的图数据库,出自于Dgraph Labs. 由一位Google前员工创办,离开Google之前就致力于研发图数据库。
0x01
正好之前有实际使用到,使用期间也遇到了很多问题,有些是在官方社区发帖提问并很快得到答复解决的,还有些提了问也没解决。
dgraph是原生分布式的、能水平扩展的、低延时的、支持集群范围AICD事务的图数据库,并且开源。
在众多benchmark中,各项指标都优于绝大多数同类数据库,noe4j老矣,尚能饭否。
何谓图数据库呢?
将所有实体作为一个数据节点,各实体又存在着各种属性,然后各个实体间又有着千丝万缕的联系。 由点到线,由线到面,最终组成形态各异的图形。
比如,每个人、动植物、及物品都是实体,各实体有年龄、性别、成分、用途等各种不同属性,人与人之间有不同的亲戚朋友关系,与宠物间有主宠关系,与物品间有拥属关系,世界由这些实体、属性、关系组成纵横交织的图谱。
图库可以描述这个真实的世界。
0x02 (描述)
dgraph有两种节点类型。Zero作为控制节点,管理分布式集群内的各个节点。Alpha作为数据节点,负责各类数据的CRUD。
这两类节点都可以增设shard副本集,副本集节点数一般设置为奇数位,方便Raft算法做节点选举。另外ratel作为可选的web UI工具可提供一个简易的数据可视化界面,方便调试
官方提供各种主流语言的SDK
内部使用grpc通讯,对外提供grpc及rest接口
0x03 (使用)
接下来以十二平均律和自然大调等做为栗子讲解如何使用dgraph
dgraph底层基于graphql,所以语法非常近似于graphql,其也支持通用的rdf语法
十二平均律作为音乐中最底层的系统,最通用的音律体系,起源于中国古代,16世纪发展为一套完善的理论,然后由西方传教士带带去西方,17世纪开始在欧洲大陆广泛流传。
规定了两个单音的相对音高,就像计算机中的二进制系统规定了各种运算方式一样。十二平均律体系将一个“纯八度”分成12份,每份称为1个半音,两份为1个全音,以此定出所有中间的单音。
在dgraph中我们将实体(当然不一定非要是可见的实体)理解为type, 将属性理解为schema, 将关系理解为edge和facet.
所以我们可以定义十二平均律的type和schema:
# 12.schema
name: string @lang @index(hash) .
pitch: float @index(float) .
pitch_interval: float @index(float) .
frequency: float @index(float) .
type the_equal_temperament_principle {
name
pitch
pitch_interval
frequency
}
通过rdf语法定义出十二个音:
# 12.rdf
<_:小二度> <dgraph.type> "the_equal_temperament_principle" .
<_:小二度> <name> "小二度"@zh .
<_:小二度> <pitch> "100.0" .
<_:小二度> <pitch_interval> "0.5" .
<_:小二度> <frequency> "105.946" .
<_:大二度> <dgraph.type> "the_equal_temperament_principle" .
<_:大二度> <name> "大二度"@zh .
<_:大二度> <pitch> "100.0" .
<_:大二度> <pitch_interval> "1.0" .
<_:大二度> <frequency> "112.246" .
<_:小三度> <dgraph.type> "the_equal_temperament_principle" .
<_:小三度> <name> "小三度"@zh .
<_:小三度> <pitch> "100.0" .
<_:小三度> <pitch_interval> "1.5" .
<_:小三度> <frequency> "118.921" .
<_:大三度> <dgraph.type> "the_equal_temperament_principle" .
<_:大三度> <name> "大三度"@zh .
<_:大三度> <pitch> "100.0" .
<_:大三度> <pitch_interval> "2.0" .
<_:大三度> <frequency> "125.992" .
<_:纯四度> <dgraph.type> "the_equal_temperament_principle" .
<_:纯四度> <name> "纯四度"@zh .
<_:纯四度> <pitch> "100.0" .
<_:纯四度> <pitch_interval> "2.5" .
<_:纯四度> <frequency> "133.484" .
<_:三全音> <dgraph.type> "the_equal_temperament_principle" .
<_:三全音> <name> "三全音"@zh .
<_:三全音> <pitch> "100.0" .
<_:三全音> <pitch_interval> "3.0" .
<_:三全音> <frequency> "141.421" .
<_:纯五度> <dgraph.type> "the_equal_temperament_principle" .
<_:纯五度> <name> "纯五度"@zh .
<_:纯五度> <pitch> "100.0" .
<_:纯五度> <pitch_interval> "3.5" .
<_:纯五度> <frequency> "149.831" .
<_:小六度> <dgraph.type> "the_equal_temperament_principle" .
<_:小六度> <name> "小六度"@zh .
<_:小六度> <pitch> "100.0" .
<_:小六度> <pitch_interval> "4.0" .
<_:小六度> <frequency> "158.740" .
<_:大六度> <dgraph.type> "the_equal_temperament_principle" .
<_:大六度> <name> "大六度"@zh .
<_:大六度> <pitch> "100.0" .
<_:大六度> <pitch_interval> "4.5" .
<_:大六度> <frequency> "168.179" .
<_:小七度> <dgraph.type> "the_equal_temperament_principle" .
<_:小七度> <name> "小七度"@zh .
<_:小七度> <pitch> "100.0" .
<_:小七度> <pitch_interval> "5.0" .
<_:小七度> <frequency> "178.180" .
<_:大七度> <dgraph.type> "the_equal_temperament_principle" .
<_:大七度> <name> "大七度"@zh .
<_:大七度> <pitch> "100.0" .
<_:大七度> <pitch_interval> "5.5" .
<_:大七度> <frequency> "188.775" .
<_:纯八度> <dgraph.type> "the_equal_temperament_principle" .
<_:纯八度> <name> "纯八度"@zh .
<_:纯八度> <pitch> "100.0" .
<_:纯八度> <pitch_interval> "6.0" .
<_:纯八度> <frequency> "200.000" .
数据都定义好了后,可以直接用写个脚本导入到dgraph:
#!/usr/bin/env python
# coding=utf-8
import pydgraph
client_stub = pydgraph.DgraphClientStub('localhost:9080')
client = pydgraph.DgraphClient(client_stub)
with open('12.schema') as f:
schema = f.read()
op = pydgraph.Operation(schema=schema)
client.alter(op)
with open('12.rdf') as f:
rdf = f.read()
txn = client.txn()
try:
mutation = txn.create_mutation(set_nquads=rdf)
request = txn.create_request(mutations=[mutation], commit_now=True)
txn.do_request(request)
finally:
txn.discard()
这时候会可能会有个问题,就是如果数据量特别大,用脚本一点点导入会特别慢,
所以当数据库里还是空的时候,我们可以直接用bulk loader生成sst文件的方式导入数据,这样会快很多
$ dgraph bulk -j 2 -s 12.schema -f 12.rdf
将生成的数据文件直接考进去alpha的数据目录就可以了
0x04 (使用)
然后呢,基于十二平均律又发展出了各种调式。自然大调就是其一,于是我们可以增设type和schema:
tonic: string @index(hash) .
MajorScale: [uid] @reverse .
type major_scale {
name
pitch
pitch_interval
frequency
tonic
}
然后确定C大调的音:
uid(纯八度) <MajorScale> <_:C> .
<_:C> <dgraph.type> "major_scale" .
<_:C> <name> "C"@en .
<_:C> <pitch> "100.0" .
<_:C> <pitch_interval> "6.0" .
<_:C> <frequency> "200.000" .
<_:C> <tonic> "C" .
uid(大二度) <MajorScale> <_:D> .
<_:D> <dgraph.type> "major_scale" .
<_:D> <name> "D"@en .
<_:D> <pitch> "100.0" .
<_:D> <pitch_interval> "1.0" .
<_:D> <frequency> "112.246" .
<_:D> <tonic> "D" .
uid(大三度) <MajorScale> <_:E> .
<_:E> <dgraph.type> "major_scale" .
<_:E> <name> "E"@en .
<_:E> <pitch> "100.0" .
<_:E> <pitch_interval> "2.0" .
<_:E> <frequency> "125.992" .
<_:E> <tonic> "E" .
uid(纯四度) <MajorScale> <_:F> .
<_:F> <dgraph.type> "major_scale" .
<_:F> <name> "F"@en .
<_:F> <pitch> "100.0" .
<_:F> <pitch_interval> "2.5" .
<_:F> <frequency> "133.484" .
<_:F> <tonic> "F" .
uid(纯五度) <MajorScale> <_:G> .
<_:G> <dgraph.type> "major_scale" .
<_:G> <name> "G"@en .
<_:G> <pitch> "100.0" .
<_:G> <pitch_interval> "3.5" .
<_:G> <frequency> "149.831" .
<_:G> <tonic> "G" .
uid(大六度) <MajorScale> <_:A> .
<_:A> <dgraph.type> "major_scale" .
<_:A> <name> "A"@en .
<_:A> <pitch> "100.0" .
<_:A> <pitch_interval> "4.5" .
<_:A> <frequency> "168.179" .
<_:A> <tonic> "A" .
uid(大七度) <MajorScale> <_:B> .
<_:B> <dgraph.type> "major_scale" .
<_:B> <name> "B"@en .
<_:B> <pitch> "100.0" .
<_:B> <pitch_interval> "5.5" .
<_:B> <frequency> "188.775" .
<_:B> <tonic> "B" .
这时候需要关联上之前定义的十二平均律的音,所以需要进行upsert操作:
package main
import (
"os"
"fmt"
"context"
"io/ioutil"
"google.golang.org/grpc"
"github.com/dgraph-io/dgo/v210"
"github.com/dgraph-io/dgo/v210/protos/api"
)
func main(){
conn, err := grpc.Dial("localhost:9080", grpc.WithInsecure())
if err != nil {
fmt.Println(err)
}
defer conn.Close()
client := dgo.NewDgraphClient(api.NewDgraphClient(conn))
ctx := context.Background()
fd, _ := os.Open("major_scale.schema")
defer fd.Close()
data, _ := ioutil.ReadAll(fd)
schema := string(data)
op := &api.Operation{
Schema: schema,
RunInBackground: true,
}
client.Alter(ctx, op)
fdr, _ := os.Open("major_scale.rdf")
defer fdr.Close()
data, _ = ioutil.ReadAll(fdr)
twelve := []string{"纯八度","大二度","大三度","纯四度","纯五度","大六度","大七度"}
query := "query{\n"
for _, x := range twelve {
query += fmt.Sprintf(`%s as var(func: type("the_equal_temperament_principle") @filter(eq(name@zh, "%s")))%s`, x, x, "\n")
}
query += "\n}"
fmt.Println(query)
mu := &api.Mutation{
SetNquads: data,
}
req := &api.Request{
Query: query,
Mutations: []*api.Mutation{mu},
CommitNow:true,
}
// Update email only if matching uid found.
if _, err := client.NewTxn().Do(ctx, req); err != nil {
fmt.Println(err)
}
}
0x05 (使用)
在中国古代,都是使用的五声调式,即宫商角徵羽。对应自然调式的CDEGA,较之少了两个半音。对应到十二平均律就是纯八度、大二度、大三度、纯五度、大六度。
同样可以追加type和schema:
Five: [uid] @reverse .
type five {
name
pitch
pitch_interval
frequency
tonic
}
五声表示成数据节点就是:
uid(C) <Five> <_:宫> .
uid(纯八度) <MajorScale> <_:宫> .
<_:宫> <dgraph.type> "major_scale" .
<_:宫> <name> "宫"@zh .
<_:宫> <pitch> "100.0" .
<_:宫> <pitch_interval> "6.0" .
<_:宫> <frequency> "200.000" .
<_:宫> <tonic> "宫" .
uid(D) <Five> <_:商> .
uid(大二度) <MajorScale> <_:商> .
<_:商> <dgraph.type> "major_scale" .
<_:商> <name> "商"@zh .
<_:商> <pitch> "100.0" .
<_:商> <pitch_interval> "1.0" .
<_:商> <frequency> "112.246" .
<_:商> <tonic> "商" .
uid(E) <Five> <_:角> .
uid(大三度) <MajorScale> <_:角> .
<_:角> <dgraph.type> "major_scale" .
<_:角> <name> "角"@zh .
<_:角> <pitch> "100.0" .
<_:角> <pitch_interval> "2.0" .
<_:角> <frequency> "125.992" .
<_:角> <tonic> "角" .
uid(G) <Five> <_:徵> .
uid(纯五度) <MajorScale> <_:徵> .
<_:徵> <dgraph.type> "major_scale" .
<_:徵> <name> "徵"@zh .
<_:徵> <pitch> "100.0" .
<_:徵> <pitch_interval> "3.5" .
<_:徵> <frequency> "149.831" .
<_:徵> <tonic> "徵" .
uid(A) <Five> <_:羽> .
uid(大六度) <MajorScale> <_:羽> .
<_:羽> <dgraph.type> "major_scale" .
<_:羽> <name> "羽"@zh .
<_:羽> <pitch> "100.0" .
<_:羽> <pitch_interval> "4.5" .
<_:羽> <frequency> "168.179" .
<_:羽> <tonic> "羽" .
导入方式同自然大调,不再赘述。
0x06 (使用)
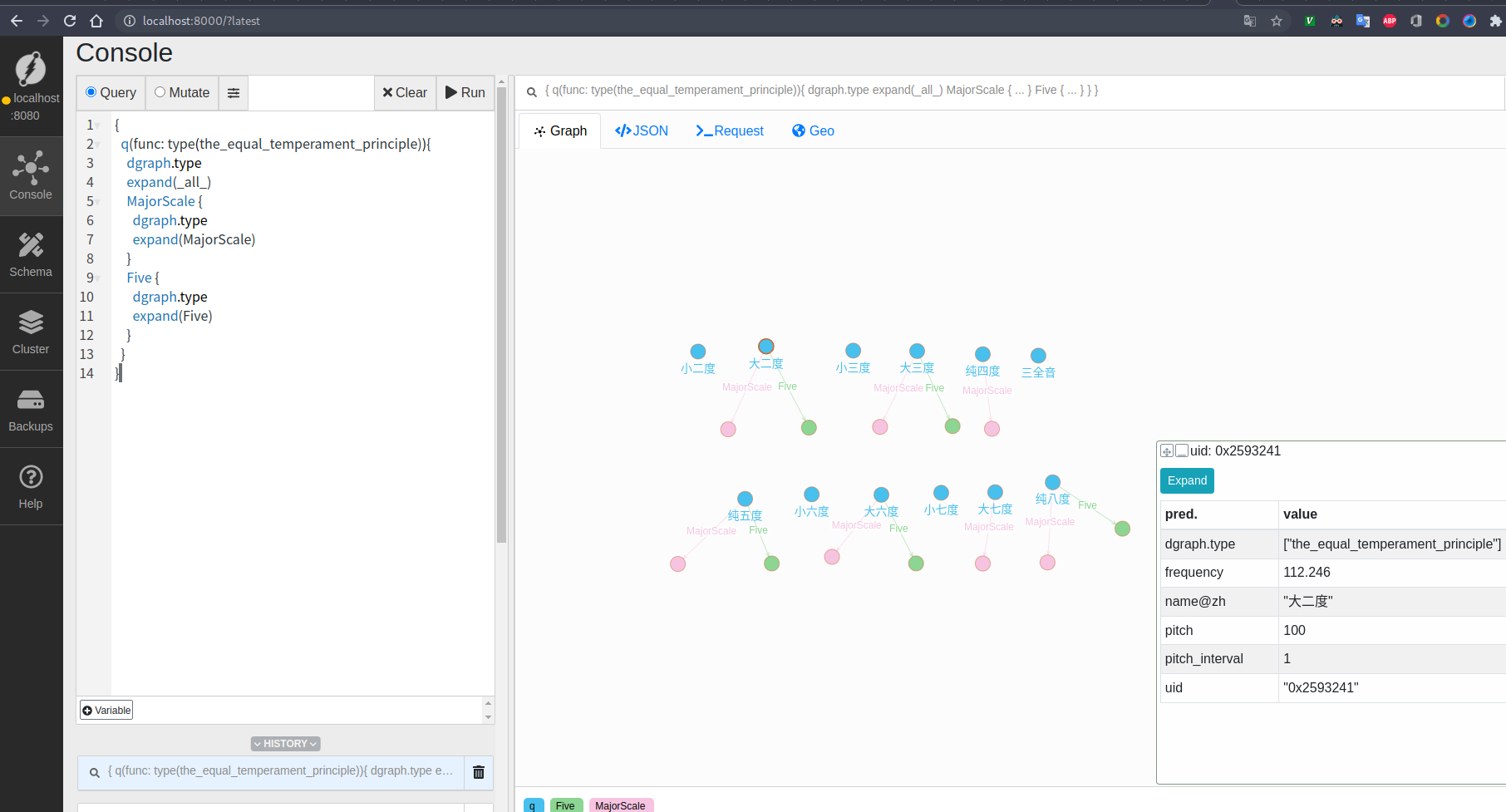
定义完这些数据后,即可查询这些节点及它们之间的关系了:
{
q(func: type(the_equal_temperament_principle)){
dgraph.type
expand(_all_)
MajorScale {
dgraph.type
expand(MajorScale)
}
Five {
dgraph.type
expand(Five)
}
}
}
以可视化图形展示出来就类似于这样:
0x07 (结束)
dgraph有很多优点,是一款很棒的图库,但也还存在一些问题。比如一个属性只能存放于一组副本集里,不会分布于不同的副本集。还有就是数据量大时特别耗内存,超过一亿数据节点并做全库CRUD时80G内存勉强抗住。